
Intelligenza artificiale o artificiosa?
Tra tecnologie del dominio e tecnologie conviviali
Norberto Patrignani (*)
“Spesso il termine utopia è la maniera più comoda
per liquidare quello che non si ha voglia, capacità o coraggio di fare.
Un sogno sembra un sogno fino a quando non si comincia a lavorarci.
E allora può diventare qualcosa di infinitamente più grande“
Adriano Olivetti (1901-1960)
(fonte: Fondazione Adriano Olivetti)
Introduzione
Il termine “intelligenza artificiale” è fuorviante fin dalla sua introduzione. Esso compare per la prima volta in una proposta di ricerca nel 1955. Tra i promotori vi sono i maggiori esperti dell’epoca: Marvin Minsky, John McCarthy, Claude Shannon, etc.
Per la storia delle tecnologie digitali, i quattro personaggi fondatori sono: Alan Turing (per la sua idea di “macchina universale”), John Von Neumann (per la definizione dell’architettura del computer che prende il suo nome), Norbert Wiener (fondatore della Cibernetica e primo scienziato del digitale a porre la questione etica, viene considerato il fondatore della Computer Ethics) e Claude Shannon (per la sua teoria dell’informazione che ha posto le basi della comunicazione tra computer).
Quando McCarthy organizza il seminario del 1955 Turing è già morto, Von Neumann è gravemente malato (lavorando con Oppenheimer al progetto Manhattan a Los Alamos ha assorbito molte radiazioni) restano Wiener e Shannon. Viene invitato solo Shannon. Quando gli storici intervistano McCarthy e chiedono: perché non avete invitato Wiener? McCarthy risponde apertamente: perché Wiener avrebbe proposto come nome per il seminario “Cibernetica” e perché Wiener già nel 1947 ha pubblicamente dichiarato il suo rifiuto di collaborare con i militari (Wiener, 1947).
Quindi il nome stesso di questa “disciplina” che viene comunemente chiamata “intelligenza artificiale” viene coniato in modo controverso, gli storici lo chiamano lo “scisma dell’informatica“. Da una parte, scienziati come Wiener seriamente preoccupati per la loro responsabilità sociale, dall’altra ricercatori a caccia di finanziamenti (la Rockefeller Foundation fornisce le principali risorse) che vedono il termine “Intelligenza artificiale” accattivante e volutamente iperbolico (Bloomfield, 1987; Nilsson, 2009). Le frasi roboanti con le quali McCarthy presenta la ricerca testimoniano l’eccesso di enfasi del tempo: “procedere sulla base della congettura che ogni aspetto dell’apprendimento o qualsiasi altra caratteristica dell’intelligenza possa, in linea di principio, essere descritto in modo così preciso che si possa realizzare una macchina in grado di simularlo” (Dartmouth, 1956). Nei settanta anni successivi la storia del digitale e la storia dell’intelligenza artificiale si intrecciano in modo stretto.
Emergono due paradigmi di programmazione dei computer: quello deduttivo e quello induttivo. Quello deduttivo, dominante fin dagli albori dell’era dei computer, trae conseguenze logiche da premesse certe (ispirato nei secoli da Aristotele fino a Descartes, Leibniz, etc.). Quello induttivo parte invece da esempi per tentare di formulare leggi più generali (ispirato da filosofi come Bacon, Locke, Hume, i cosiddetti “empirici”). L’approccio deduttivo ha prodotto la maggior parte del software che usiamo nel mondo, il cosiddetto software algoritmico. L’approccio induttivo invece si è diffuso in modo esplosivo negli ultimi anni, il cosiddetto software statistico, basato sulle reti neurali artificiali, comunemente e genericamente definito “intelligenza artificiale”. Perché?

Un po’ di storia
Molto schematicamente la storia dell’informatica si può dividere in tre grandi epoche. La prima, quella dei grandi computer, inizia attorno al 1950, vede le risorse principali della macchina (memoria e unità di elaborazione) centralizzate. I computer hanno grandi dimensioni e l’accesso alla macchina è riservato alle persone addette alla sua custodia. Va ricordato che il primo computer della storia completamente a transistor (quindi più affidabile, i primi computer erano a valvole!) è l’ELEA-9003 costruito dalla Olivetti di Ivrea nel 1959.
La seconda era dei computer si può identificare con il Personal Computer: nel 1965 per la prima volta una persona ha a disposizione sulla sua scrivania una macchina completa, incluse memoria e unità di elaborazione. Il primato spetta ancora una volta alla Olivetti: il primo PC della storia è l’Olivetti P101 del 1965 (WSJ, 1965). L’era del PC fa intravedere un’informatica decentrata che rende accessibile la tecnologia digitale con macchine economiche. Nel 1973 nasce la rete Internet e nel 1989 nasce il World Wide Web: con un semplice computer ci si può connettere in modo “paritario” con altri computer in qualsiasi punto del pianeta e con un semplice click si accede ai grandi “depositi della conoscenza”. Questo sogno però dura poco.
Nel 1996 il Congresso degli Stati Uniti approva la più grande riforma delle telecomunicazioni della storia: il Telecommunication Act, una delle più grandi operazioni di “deregulation”. In pochi anni inizia una gigantesca corsa al consolidamento di veri e propri imperi monopolistici: nascono le Big Tech (Durand, 2024). Le tecnologie digitali si rivelano piattaforme per la raccolta indiscriminata dei dati, la manipolazione e la sorveglianza. Risultato: una concentrazione di potere di elaborazione, di memorizzazione, di ricchezza e di potere politico forse mai vista nella storia dell’umanità (Zuboff, 2019). Per avere un’idea della immensa ricchezza accumulata, in termini finanziari, tra le prime dieci imprese più grandi del mondo a Dicembre 2025 ben sei sono le Big Tech: Nvidia (4.441 Miliardi di dollari), Apple (4.137), Google (3.888), Microsoft (3.591), Amazon (2.453), Meta-Facebook (1.697). Per confronto, il PIL dell’Italia è stato di 2.300 Miliardi di dollari (Forbes, 2025; WorldBank, 2024).

“Intelligenza artificiale” o macchine calibrate con (tanti) dati?
Dal punto di vista tecnologico la quantità di dati e la potenza di calcolo accumulati hanno creato le basi per l’esplosione della cosiddetta “intelligenza artificiale”. Infatti il paradigma induttivo per la programmazione dei computer si basa su un’idea molto semplice: quando non ci sono sufficienti regole consolidate per poter risolvere un problema, descrivere la soluzione con un algoritmo e farlo eseguire da un computer (approccio deduttivo) bisogna ricorrere a degli esempi. Un classico problema senza algoritmo è quello del riconoscimento della scrittura a mano: anche solo restringendo il dominio ai dieci numeri da zero a nove, è impossibile scrivere un programma in grado di riconoscere un numero scritto a mano. E allora che si fa?
Si prendono migliaia di esempi di numeri scritti a mano. Ogni numero si può definire come una immagine, es. una matrice di 28 x 28 = 784 pixel, ciascun pixel è un puntino luminoso, nel caso più semplice di immagine con pixel in bianco e nero con 256 livelli di grigio, il numero da riconoscere è costituito da 784 byte, ogni byte descrive un pixel con i suoi 256 valori (es. da 0, nero a 255, bianco e tutti i livelli di grigio intermedi). Immaginiamo ora una rete con 784 nodi in ingresso, ogni nodo in ingresso è connesso con una prima serie di 16 nodi. Ogni nodo della prima serie è a sua volta connesso con una seconda serie di 16 nodi. Infine la seconda serie di 16 nodi è connessa con una serie di 10 nodi in uscita. Ogni connessione ed ogni nodo sono rappresentati con un numero reale da 0 a 1. All’inizio la rete (i nodi e le connessioni) contiene numeri casuali e quindi fornendo in input un’immagine di un “3” scritto a mano (ovvero 784 pixel in bianco e nero) le 10 uscite contengono anch’esse numeri casuali.
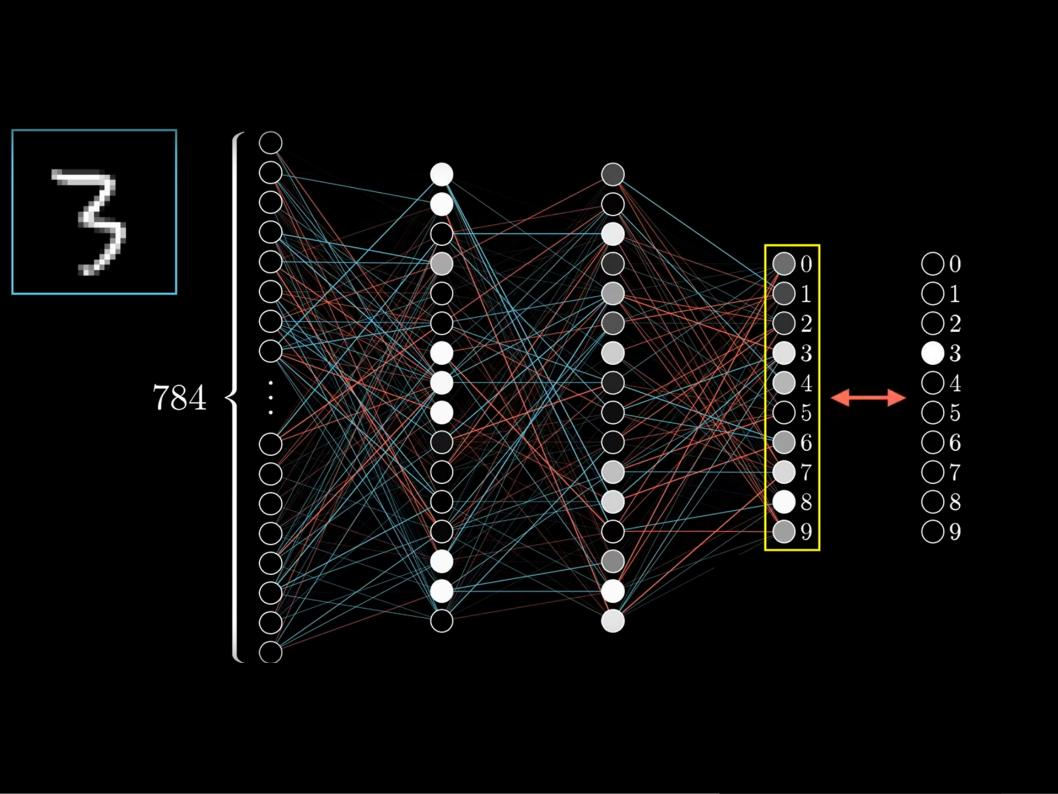
fig.1 (la rete che riconosce numeri scritti a mano)
Ma l’obiettivo ideale sarebbe quello di avere solo l’uscita “3” contenente un 1 e tutte la altre uscite 0 (fig.1). Immaginiamo ora di riuscire a “correggere” i numeri che descrivono i nodi e le connessioni in modo tale che, quelli che portano verso l’uscita giusta “3” vengono aumentati, quelli che portano verso le altre uscite errate diminuiti.
Al secondo tentativo si immette un altro “3” scritto a mano (ovvero la sua immagine in forma di 784 pixel) e si corregge la rete come prima, si ripete il procedimento molte volte, etc. ad un certo punto l’uscita corrispondente al “3” sarà vicina al valore 1 (ad esempio 0,94) tutte le altre saranno vicine al valore 0 (ad esempio 0,07 – 0,01, etc.).
Quando ci si ferma? Quando si ritiene “accettabile” il valore corrispondente alla risposta giusta. Più precisamente quando. immettendo un certo numero di immagini di “3” scritti a mano, la rete fornisce in uscita una percentuale “accettabile” (es. 96%) di risposte giuste. Questo implica che in un 4% dei casi la rete può sbagliare. Proprio per questo si parla di software statistico.
Per avere un’idea della quantità di dati in gioco, questa semplice rete è descrivibile con circa 13.000 dati (i cosiddetti “pesi” dei nodi e delle connessioni), una rete simile a quelle dei grandi modelli del linguaggio (Large Language Models, LLM) come ChatGPT, Gemini, Claude, etc. contiene migliaia di miliardi di “pesi”. Ecco perché la loro “calibrazione” richiede immense quantità di dati, di potenze di calcolo, di energia e di acqua. La procedura di “calibrazione” o correzione degli errori dei pesi (nota come “back propagation“) è dovuta a Geoffrey Hinton che vince per questo il Premio Nobel per la Fisica.
Per arrivare ai giorni nostri dobbiamo citare due passi chiave: il primo è la più grande raccolta di immagini “etichettate” che servono per la fase di “calibrazione” e test delle reti di nodi (spesso chiamate “reti di neuroni artificiali”). Nel 2009 Fei Fei Li, la direttrice del Laboratorio di Intelligenza Artificiale dell’Università di Stanford mette insieme 14 Milioni di immagini etichettate, classificate in oltre 20.000 categorie: nasce la base dati di riferimento ImageNet. Ma chi ha messo manualmente le etichette su questi milioni di immagini? Migliaia e migliaia di persone da centinaia di paesi diversi (tipicamente nel Sud del mondo) ingaggiate per pochi dollari al giorno tramite la gigantesca “agenzia di collocamento” per “micro-lavori” Amazon Mechanical Turk (Casilli, 2020; Poulain, H. 2025). Pochi anni dopo è la stessa Li ad ammettere la “lamancanza di trasparenza intrinseca nella sua progettazione …” (Li, 2023).
Il secondo passo chiave di questa storia avviene nel 2012 con la progettazione della rete Alexnet da parte di Geoffrey Hinton e di due suoi studenti, Alex Krizhevsky e Ilya Sutskever dell’Università di Toronto in Canada. La rete Alexnet, costituita da oltre 600.000 parametri, risulta la più precisa nella classificazione di immagini. Appena presentato il lavoro, ricevono telefonate con offerte da tutte le principali imprese del digitale, decidono di fare un’asta online (!): vincerà Google con 44 Milioni di dollari (Krizhevsky, Sutskever, Hinton, 2017). Curiosamente anche Hinton, dopo pochi anni, ha un “momento Oppenheimer“, come diranno i giornalisti: con una clamorosa intervista al New York Times, il 1 Maggio 2023, rassegna le dimissioni da Google e denuncia i rischi per la società legati alla diffusione di macchine che renderanno sempre più difficile capire cosa è vero e cosa è falso (Merz, 2023). Con conseguenze sociali preoccupanti: “…già oggi il caos epistemico è arrivato a livelli pericolosi, cosa avverrà quando diventa così facile diffondere mala-informazione (informazione vera, effettiva, diffusa tipicamente fuori contesto), mis-informazione (informazione falsa e fuorviante, creata e diffusa senza l’esplicita intenzione di ingannare, purtroppo percepita e ritrasmessa come fosse vera), dis-informazione (informazione falsa, diffusa con l’esplicita intenzione di ingannare le persone, polarizzare l’opinione in gruppi incomunicanti, senza vie intermedie, fino alle conseguenze estreme)?” (Patrignani, 2023).
Si rischia di perdere il pensiero critico, il metodo scientifico come spiega David Gros, Premio Nobel per la Fisica: “osservare, formulare ipotesi, verificare e replicare sono i fondamenti del metodo scientifico … l’intelligenza artificiale, per quanto potente e affascinante, si muove su un terreno completamente diverso: non osserva, non verifica, non replica… si limita a calcolare la risposta più probabile” (Dotti, 2024).
E per questo ha bisogno di immense quantità di dati. Ecco spiegato perché l’approccio induttivo è esploso negli ultimi anni: perché solo una manciata di organizzazioni hanno i data center delle dimensioni e della capacità di memoria e di elaborazione adeguati alla calibrazione di queste reti gigantesche. Tutto questo ha scatenato l’ennesima “corsa agli armamenti” tra le Big Tech statunitensi e quelle cinesi: i consumi elettrici dei data center globali passeranno dai 536 Miliardi di kWh del 2025 ai 1.065 Miliardi di kWh nel 2030; mentre il numero dei data center passerà dai 5.709 del 2024 ai 8.378 del 2030 (Wong, 2024; Goldman Sachs, 2024).
Le ultime stime sul numero di utenti danno circa 1,8 Miliardi di persone che si connettono regolarmente agli LLM (KPMG, 2025).

I rischi principali
Come si è accennato, il costo ambientale e sociale di queste macchine è ormai insostenibile. Ma vi sono altri rischi più sfuggenti come il cedimento epistemologico: si scivola in modo quasi inconsapevole dall’usare le macchine digitali per fare previsioni (le previsioni del tempo sarebbero impossibili senza computer), all’usare le macchine per fare predizioni (la manutenzione predittiva è ormai una pratica consolidata) fino ad arrivare a delegare alla macchina le prescrizioni. (anche in contesti dove sarebbe importante la supervisione e l’assunzione di responsabilità delle scelte da parte dell’umano, si pensi alle scelte negli ospedali, nei tribunali). Fino ad arrivare al dilemma etico più antico per gli umani: è giusto delegare ad un’arma automatica la scelta di uccidere? Le cosiddette “armi letali autonome” (LAWS, Lethal Autunomous Weapon Systems) sono oggetto di una campagna internazionale per la loro messa al bando, al pari delle armi chimiche, batteriologiche e nucleari: la campagna Stop Killer Robots produce molti materiali per sensibilizzare (vedi il documentario “Immoral Code” https://www.stopkillerrobots.org/take-action/immoral-code/). Purtroppo diversi rapporti dell’ONU certificano l’uso di queste armi e dell’intelligenza artificiale fornita dalla Big Tech in diversi scenari di guerra (Oliveri, 2025).

Che fare?
Innanzitutto è fondamentale capire, essere consapevoli che queste sono macchine, una pluralità di macchine, e per evitare la trappola dell’antropomorfizzazione, evitare di accettare la prima persona usata da una macchina quando risponde “Io, etc.” (io chi?).
Come si è visto, queste macchine sono basate sulla programmazione induttiva che ha bisogno di (tanti) dati, allora chiamiamola con un termine più preciso dal punto di vista scientifico: “macchine calibrate con (tanti) dati” (Patrignani, 2023), oppure per essere ancora più chiari “intelligenza artificiosa“.
Da un punto di vista tecnologico ci sono degli sviluppi interessanti: il paradigma californiano “bigger is better” sembra in declino e cominciano ad essere disponibili degli LLM che possono essere installati sul proprio PC! Si parla di ricerche sulla IA distribuita. Diventa possibile utilizzare LLM di dimensioni contenute e soprattutto senza doversi collegare alle Big Tech (Apertus, 2025).
Iniziano ad esserci imprese digitali che si ispirano ad un modello Slow Tech (Patrignani e Whitehouse, 2018): verso un’informatica buona (centrata sull’umano), pulita (che minimizza l’impatto ambientale) e giusta (che cura in modo particolare le condizioni di lavoro). Un esempio: fairphone. Iniziano ad esserci soluzioni, servizi, applicazioni che si ispirano alle tecnologie conviviali, ovvero “strumenti (digitali) che garantiscano alle persone il diritto a lavorare in autonomia“(Illich, 1973). Le quattro principali caratteristiche che devono avere le tecnologie (digitali) conviviali sono:
– aperte e libere, quindi riscoprire che tra i tanti beni comuni c’è anche la conoscenza; si deve poter vedere come sono fatte; quindi formati aperti e hardware e software libero!
– comunitarie, deve esserci una comunità che le sviluppa e le aggiorna, che condivide la conoscenza e che aiuta supportando le persone, anche in luoghi fisici dove potersi incontrare;
– decentrate, non deve esserci un centro di potere, un centro dal quale dipendono tutti (la tecnologia non è neutra! Tecnologia e società si plasmano a vicenda!); una architettura decentrata (e federata) è anche più resiliente dal punto di vista tecnico;
– infine interoperabili, le persone devono poter spostare i loro dati liberamente, da un ambiente a un altro e continuare a lavorare.
Alcuni esempi: signal (al posto di whatsapp!), libreoffice (writer, calc, impress), draw, base, math, firefox, openstreetmap, wikipedia, framatalk, framagenda, framadate, framaforms, framapad, tutanota, protonmail, mastodon (al posto di facebook!), pixelfed, peertube, nextcloud, linux, etc. (Patrignani, 2025).
Uno degli aspetti più critici è l’assenza di piattaforme su base europea ma anche su questo ci sono ricerche molto interessanti che richiederebbero un coordinamento e finanziamento europeo, per liberarsi dalle “tecnologie del dominio” delle Big Tech, es. il progetto Eutostack (Bria, Timmers, Gernone, 2025).
Certo alcune di queste tecnologie richiedono persone esperte, ma d’altra parte la caratteristica comunitaria serve proprio a superare la “collezione di solitudini” della rete. Sembra un’utopia? Sembra un sogno? Come diceva Adriano Olivetti: “Un sogno sembra un sogno fino a quando non si comincia a lavorarci.“

Riferimenti
– Apertus (2025). https://www.swiss-ai.org/apertus
– Bloomfield B.P. (1987). The question of artificial intelligence, Routledge.
– Bria, F., Timmers, P,, Gernone, F., (2025). EuroStack – A European Alternative for Digital Sovereignty. Bertelsmann Stiftung. Gütersloh.
– Casilli, A. (2020). Gli schiavi del click, Feltrinelli.
– Dartmouth (1956). Artificial Intelligence Coined at Dartmouth 1956, dartmouth.edu.
– Dotti, G. (2024, 8 Dicembre). L’intelligenza artificiale può essere un rischio per la ricerca, Sole24Ore.
– Durand, C. (2024, 8 Aprile). The Rise of Big Tech Is Generating Economic Stagnation, Jacobin.
. Forbes (2025). Top ten companies in the world, forbes.com.
– Goldman Sachs (2024). AI, data centers and the coming US power demand surge,
– Illich, I. (1973). Tools for conviviality. Harper & Row.
– KPMG (2025). Trust, attitudes and use of artificial intelligence: A global study 2025.
– Krizhevsky, A., Sutskever, I, Hinton, G. (2017). ImageNet classification with deep convolutional neural networks, Communications of the ACM. 60 (6).
– Li, F.F. (2023). The Worlds I See, Flatiron, p.284.
– Merz, C. (2023, 1 Maggio). The Godfather of A.I.’ Leaves Google and Warns of Danger Ahead, The New York Times.
– Nilsson, H.J. (2009). The Quest for Artificial Intelligence, Stanford University, pag.78.
– Oliveri, F. (2025). Il ruolo delle Big Tech nel genocidio di Gaza, Centro Interdisciplinare Scienze per la Pace (CISP), Università di Pisa.
– Patrignani, N. Whitehouse, D. (2018). Slow Tech, Palgrave.
– Patrignani, N. (2023). Non chiamiamola “intelligenza” artificiale, IlMulino rivista.
– Patrignani, N. (2025). La bicicletta digitale. Esistono tecnologie (digitali) conviviali?, Centro Studi Sereno Regis.
– Poulain, H. (2025). In the belly of AI, federationstudios.com.
– Wiener, N. (1947). A scientist rebels, The Atlantic.
– Wong, Y. (2024). How Many Data Centers Are There and Where Are They Being Built?
– WorldBank (2024). Italy GDP, worl bank open data.
– WSJ (1965, 15 Ottobre). Desktop Size Computer is Being Sold by Olivetti for First Time in US, Wall Street Journal.
– Zuboff, S. (2019). Il capitalismo della sorveglianza. Il futuro dell’umanità nell’era dei nuovi poteri, Luiss University Press.

*) Norberto Patrignani – Ha insegnato Computer Ethics al Politecnico di Torino. Attualmente collabora come volontario con il museo Olivetti di Ivrea, il Centro Studi Sereno Regis di Torino e l’associazione Informatici Senza Frontiere. E’ Rappresentante nazionale italiano al TC9-Technology and Society dell’IFIP (International Federation for Information Processing) e membro del ACM (Association for Computing Machinery) Committee on Professional Ethics.
Dal 1974 al 1999 ha lavorato alla Ricerca Olivetti di Ivrea. Si è diplomato nel 1974 in Elettronica all’ITI “Montani” di Fermo, laureato in Informatica all’Università di Torino e conseguito il dottorato (PhD) in Computer Ethics alla Uppsala University, Svezia. Ha pubblicato molti articoli e libri sui temi dell’innovazione responsabile e dell’etica digitale.